
Extracting data from multiple websites for use in web applications is a common practice, popularly known as web scraping. The best example of which can be found in travel booking websites like Expedia, ebookers, etc. which gather data from multiple airlines and hotels’ websites to provide you with the details you’re looking for. This is actually a pretty complex process, which requires an efficient scraping method that get the results quickly and efficiently.
There’s two ways to extract data from other sites. One is to use their public API (if available) and the other is to crawl their site automatically and extract data from the web pages. The latter process is what is known as web scraping. And there’s a number of scraping frameworks or tools available that you can use for this purpose, the most popular being Python’s open source framework Scrapy. In this post we’re going to look at the basics of the Scrapy framework and how you can use it to extract or scrape data from other websites.
To get started you’ll need to first install Python. To do that just follow the steps below.
Now open up console and type “python –version” and it should work. You’ll see the following screen if Python has been successfully installed.

The biggest advantage of using Scrapy is that you only need to have a basic understanding of Python to use it. There’s no in depth knowledge required. The only things you need to be familiar with are Python’s:
1. Syntax, Types and Operators
2. Conditions, Loops, Functions and Classes
3. Lists and Dictionaries
4. Built-in functions of Strings, Lists and Dictionaries and
5. How Python manages Modules and Packages
You can refer the following tutorial to learn more about these. It’ll help save you time.
http://www.tutorialspoint.com/python/index.htm
For a Python editor, you can use the JetBrains Pycharm community edition. So let’s get started.
Since Scrapy is basically a Python package it offers a number of benefits over other frameworks such as:
To proceed with the tutorial you’ll first need to install Scrapy, by following the steps below.

That will install the pip manager. Next, verify that the installation has been completed successfully by using the following command. You’ll see the message below if the installation was successful.
The pip manager will take care of installing Scrapy and all of its dependencies. All you need to do is run the following command.

Note
If you encounter any missing module errors, try to install that module/package individually using the command:
“pip install <module_name>”
Next, verify the installation by typing the following command.
Now, let’s create our first Scrapy project using the command “scrapy startproject <project_name>” as shown below.
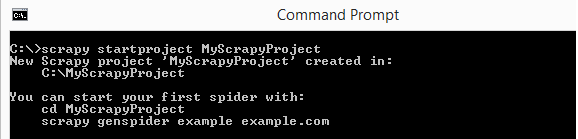
This command will create a basic templated project at the path where you run it. The directory and associated files for this project will be as follows:
MyScrapyProject – this is the main project’s parent directory that contains Scrapy’s configuration file
MyScrapyProject – This project directory is a python package.
spiders – This is the folder that holds all the scraping scripts. In Scrapy these scripts as known as “Spiders”. These consist of the following:
__init__.py – A default initializer for the spider sub-package
__init__.py – A default initializer for the MyScrapyProject package
items.py – This is a templated file for Scrapy items. Here you can define the fields that need to be scraped from web pages into CSV files as properties of the scrapy.Item class.
pipelines.py – This is a file where Scrapy’s provided pipeline classes are maintained. These pipelines provides the callback functions whenever a Scrapy Item is being processed.
settings.py – This is the main settings file for the Scrapy project where multiple types of provided settings can be configured.
scrapy.cfg – This is the auto generated file by the project where the project’s settings module and deployment path can be managed.
To create your first Spider in Scrapy have a look at this example http://www.flaticon.com/packs/?sort=a .
When you go to this URL you’ll see several packs of icons. Each has its own detailed page that shows the icons available in that pack. By clicking on any icon you will land on that icon’s details page. Let extract some fields and images from there as shown below
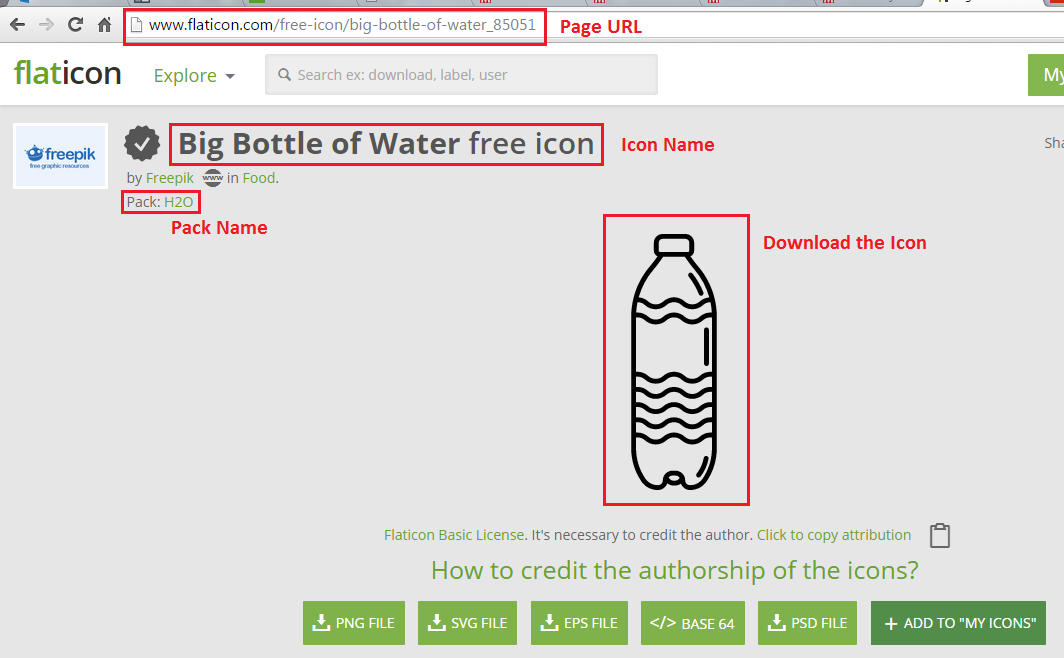
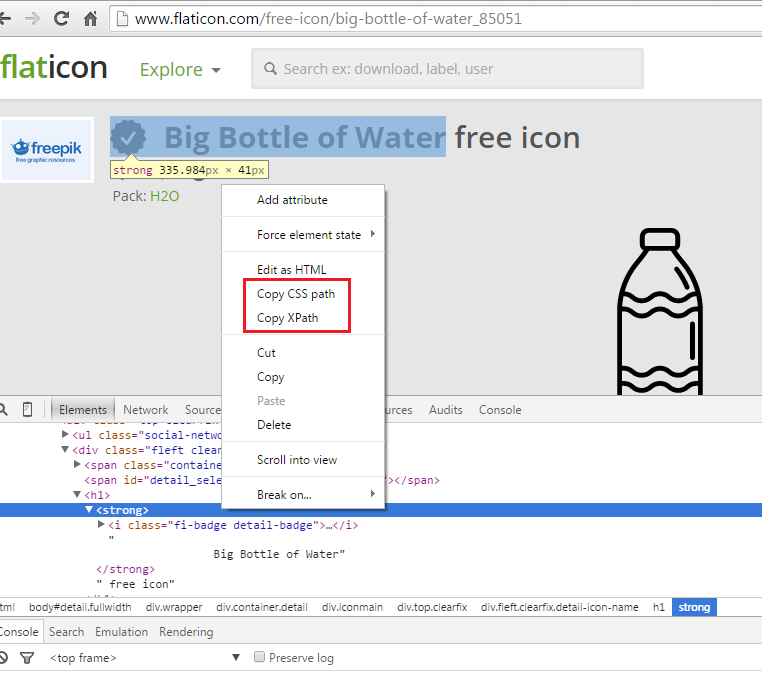
To extract the fields depicted in the screenshot above, we can use either CSS selectors OR Xpath selectors, both of which are readily available in the Chrome developer tools and also in Firebug (depicted below).
Now open the items.py file and replace its code as follows:
{
# from scrapy module include the Item and Field classes
from scrapy import Item, Field
# Our item class derived by the Base Item class
class MyscrapyprojectItem(Item):
# Field to store icon name
icon_name = Field()
# Field to store pack name
pack_name = Field()
# Field to store url of the page
page_url = Field()
# Predefined field by files pipeline. List of files urls put here to download
file_urls = Field()
}
Note
In the above code snippet, the description is provided in the comments (in green) while the code itself is in blue. After adding the code you can adjust the line indentation as needed.
Next, add the following lines in the settings.py file which are required Scrapy in order to automatically download the svg icon.
{
# The builtin pipeline to download files
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
# Path where the downloaded files will be store
FILES_STORE = 'C:/MyScrapyProject/'
Now you’re ready to to add your spider. Create a file flaticon.py in the spiders folder and paste the following code in it.
#first importing the required classes from their modules
from scrapy.spider import Spider
from scrapy.selector import Selector
from scrapy.http import Request
from MyScrapyProject.items import MyscrapyprojectItem
#Our derived Spider class that contains the code of scraper
class Flaticon(Spider):
#Required name field. This is the identifier of this spider
name = "flaticon"
"""Required list of starting urls where crawling should start that can be multiple
If multiple urls use here then they will crawl in parellel asychoronously"""
start_urls = ["http://www.flaticon.com/packs/?sort=a"]
"""The default parsing function of spider, when response was downloaded
from respective start_urls"""
def parse(self, response):
#Making the selector object that provides css and xpath methods
sel = Selector(response)
"""Links of packs extracted here in a list using css selector. Then for
each link yields the Request object to packs detail page after setting
the callback function. All the request will be yield asynchronously
in parallel"""
links = sel.css("div.categoryList a.cattitle::attr(href)").extract()
for link in links:
yield Request(link, self.parse_pack)
#The callback function once response was downloaded from pack's detail page
def parse_pack(self, response):
sel = Selector(response)
"""Similarly on the pack's detail page getting links of icons here
and yielding them as Request to their detail page"""
links = sel.css("div.glyph-container a.see::attr(href)").extract()
for link in links:
req = Request(link, callback=self.parse_file)
yield req
#The callback function when the response from its respective icon detail page received
def parse_file(self, response):
sel = Selector(response)
"""First creating the Item object here that is require by the pipeline in order
to write the scraped fields to csv. Also used xpath selector here in pack_name
and response object gives us the url of the page actually"""
item = MyscrapyprojectItem()
item['icon_name'] = sel.css("div.detail-icon-name h1 strong::text").extract()[1].strip()
item['pack_name'] = sel.xpath('//div[@class="detailAuthor"]/span[3]/a/text()').extract()[0].strip()
item["file_urls"] = sel.css('#originalSvg::attr(src)').extract()
item["page_url"] = response.url
"""And finally yield the item to save it in csv and download the icon files.
All the Request and Items yielded asynchronously by default 16 max at a time"""
yield item
After pasting the above code just run the following command which uses the spider’s name you specified above i.e. flaticon. The -o parameter used here is basically asking for the output to be given in a CSV file titled output.csv
Scrapy logs all the messages and statuses generated on the console itself while crawling. It will also show you the stats of the crawling/scraping process once the crawler stops, such as the number of items requested, the number of downloaded files, total number of Http requests, etc.
Once the spider closes (stops running), be sure to verify your output CSV in the C:/MyScrapyProject/output.csv file and also the downloaded svg icons on C /MyScrapyProject/full/
When you open the output.csv file you’ll see that a complete directory has been created by scrapy that separates the full size images of the icons from their thumbnail sizes. Since these thumbnails can also be configured in the settings.py file, the downloaded files have also been renamed by Scrapy with an auto generated MD5 hash, so that when the next time spider runs the next time around, it will not download these same files again

In this post you learnt about the basics of web scraping and architecture and usage of the Scrapy tool. But this not all that Scrapy can do. Scrapy also has a lot of other cool features that you check out. For details on these other features have a look at http://doc.scrapy.org/en/1.0/intro/tutorial.html
As a leading mobile app development company (iPhone, Android, Windows Phone, HTML5 app development), Folio3 specializes in native app development services and cross platform mobile app development services for the iPhone and iPad. We also offer extensive mobile app testing and QA services. If you have a mobile app idea that you’d like to discuss please or would like to know more about our iPhone app development services, please Contact Us. Learn more about our iPhone, Android and Windows Phone app development services.
USA408 365 4638
1301 Shoreway Road, Suite 160,
Belmont, CA 94002
Whether you are a large enterprise looking to augment your teams with experts resources or an SME looking to scale your business or a startup looking to build something.
We are your digital growth partner.
Tel:
+1 (408) 412-3813
Support:
+1 (408) 512 1812


COMMENTS ()
Tweet