
The domain of speech recognition is considered as one of the most promising areas where modern machine learning tools are coming in handy in our quest to further refine and improve accuracy of the transcripts.
The advent of ML frameworks such as Tensorflow, Theano and Torch are proving to be very useful in these cases. For example, Google’s Speech utilizes Tensorflow for its Speech to text conversion. While other solutions are still in their infancy stages, this domain is still considered to be the next HOT area of the tech industry.
One such service is the IBM Watson. Watson provides a plethora of cognitive abilities such as Natural Language Processing/Understanding, Text to Speech synthesizer etc. Speech to Text is another service provided by Watson.
While there is still room for improvement in all transcription services, IBM’s Watson stands out among its competitors in business. For a detailed review, please check out our blog: A COMPARISON BETWEEN DIFFERENT SPEECH TO TEXT SERVICES.
Let’s begin with creating a blank project. For this purpose we are going to execute a maven command that will create a barebones project directory with the pom.xml.
mvn -B archetype:generate \ -DarchetypeGroupId=org.apache.maven.archetypes \ -DgroupId=com.folio3.app \ -DartifactId=speech-to-text
This command will generate a skeleton project with the below directory structure:
speech-to-text |-src | |-main | |-java | |-com | |-folio3 | |-app | |-App.java |-test | |-java | |-com | |-folio3 | |-app | |-AppTest.java
In this step, we will add our dependencies to the project. Since, we planned to use Spring Boot for our framework requirements so we are first going to add the Spring Boot dependency to our project POM file inside the <dependencies></dependencies> tag.
In this post, we are going to implement a simple speech recognition task using Spring Boot and Watson’s Java SDK. This task will provide an audio file to the Watson API and return us with a transcription for the audio. We could have built a console application for the ease of it, but who builds console applications these days.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>1.5.2.RELEASE</version>
</dependency>
<dependency>
<groupId>com.ibm.watson.developer_cloud</groupId>
<artifactId>speech-to-text</artifactId>
<version>4.2.1</version>
</dependency>
Now we are going to update our main method to bootstrap the Spring environment for us. For this we will need to modify App.java as such:
package com.folio3.app; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; /** * Bootstrap the Speech To Text application * @author Fahad Zia <[email protected]> */ @SpringBootApplication public class App { public static void main(String[] args) { SpringApplication.run(App.class, args); } }
But before we start working on our controller. We will need to create a model that will represent our object model from the request, since we will be utilizing the API as a Rest Service. The model will only contain audio member variable that will contain the base 64 encoded audio.
package com.folio3.app.models;
public class SpeechPost {
private String audio;
public String getAudio() {
return audio;
}
public void setAudio(String audio) {
this.audio = audio;
}
}
We will now create a controller under a new folder in the com.folio3.app directory. This automatically translates to a package in terms of java. We will name our controller SpeechTranscriber.java and will contain the following contents.
package com.folio3.app.controllers;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.bind.annotation.ResponseBody;
import com.folio3.app.models.SpeechPost;
@RestController
@RequestMapping("/speech")
public class SpeechTranscriber {
@ResponseBody
@RequestMapping("/transcribe")
public String transcribe(SpeechPost post) throws Exception {
String text = null;
//return the transcript
return text;
}
}
So this is how our controller looks like. If you’re thinking this does not look complete, then you’re absolutely right. So let’s start with decoding the audio received as a Base-64 string first.
byte[] byteArray = Base64.getDecoder().decode( post.getAudio() );
Next, We will store this into a temporary file.
File tempFile = File.createTempFile("speech-", ".wav", null);
FileOutputStream fos = new FileOutputStream(tempFile);
fos.write(byteArray);
fos.close();
Now, we will instantiate the Watson Speech to Text service and execute the recognize API call.
SpeechToText service = new SpeechToText();
service.setUsernameAndPassword( "<username>", "<password>" );
RecognizeOptions options = new RecognizeOptions.Builder()
.contentType(HttpMediaType.AUDIO_WAV) //select your format
.build();
SpeechResults result = service.recognize(tempFile, options).execute();
Please note that the API username and password can be generated on the IBM BlueMix Developer’s Console. So only the credentials generated for Speech to Text should be used here.
Next, we will refine the result object and return the final transcript generated by IBM Watson.
String text = null;
if( !result.getResults().isEmpty() ) {
List<Transcript> transcripts = result.getResults();
for(Transcript transcript: transcripts){
if(transcript.isFinal()){
text = transcript.getAlternatives().get(0).getTranscript();
break;
}
}
}
return text;
If you have followed and understood so far. Your controller should be pretty similar to what we have here.
That’s it for the server right now. BUT.
For this purpose, we’ll utilize a little bit of jQuery ajax and HTML. Firstly, let’s define a simple HTML form with File field for the audio file and a simple submit button.
<form id="folio3-watson-transcription-form">
<input name="audio-file" id="audio-file" type="file" />
<input name="submit" id="submit-file" type="submit" value="Transcribe!" />
</form>
<div id="transcript"></div>
Note: The div element with the id “transcript” will only display the transcript text.
This was the simple part, now let’s bind a submit event to this form, that will read the contents of the file, convert them to Base-64 and post it to our REST api. Firstly, let’s bind the event like this:
$('#folio3-watson-transcription-form').click(function (e) {
e.preventDefault();
});
Secondly, we will create a function that will invoke the API call with the data.
function postData( audioString ) {
//build the form data
var data = new FormData();
data.append( 'audio', audioString );
//execute the post request
var jqxhr = $.ajax({
type: "POST",
url: "/speech/transcribe",
data: data,
processData: false,
contentType: false,
success: function( result ) {
$('#transcript').html( result );
}
});
}
Thirdly, we need to convert the file into Base-64. The reason for doing this is simplicity, we can do this using Multipart in Spring Boot, but it is much simpler to utilize Base 64 when dealing with JSON objects. So let’s proceed with the Base 64 conversion.
var file = new FileReader();
file.onload = function (e) {
var base64Audio = this.result;
postData( base64Audio.split(',')[1]) ); //remove the preceding contentType from the string
}
file.readAsDataURL( $('#audio-file')[0].files[0] );
The contents above can be plugged into the submit event we defined earlier. This completes our file conversion and API invocation calls from the front-end.
Now, Let’s run the project and see how this works. To start a Spring Boot project, you need to run the following command in the root directory of your project i.e where the pom.xml is placed.
mvn spring-boot:run
This will spin up our project on the default 8080 port of your localhost. Let’s browse to http://localhost:8080 to see first-hand, how it looks like.
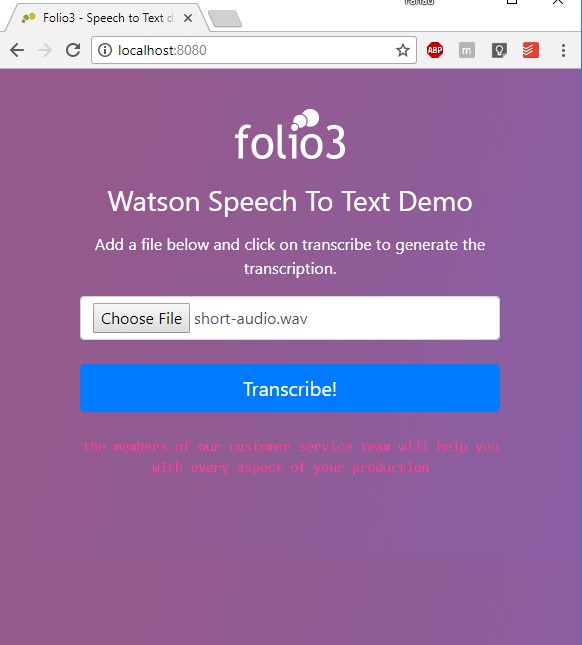
You can see the transcript of the audio just below the submit button.
This concludes our implementation of the Watson Java SDK for its Speech to Text service. We hope that you will find this useful.
You can find the complete source code at our Github repository here: https://github.com/folio3/watson-speech-to-text/
This was an example for synchronous transcription of the audio. This means that we provided a complete file to the service and it generated a single response with transcript.
There is also an asynchronous way of generating the transcript in which we provide the audio file/data as a stream and it generates the transcript in real-time. This is done by utilizing web sockets. But there are some limitations to this.
While working with the Watson Java SDK, we encountered some limitations within the SDK for real time transcription. This limitation appeared when the stream was discreet i.e when the data was not continuous (or is being received in chunks).
Watson provides a client side SDK (Javascript) that would have resolved the issue but that would have completely bypassed our server and that is what we did not want. To overcome this limitation we had to override some Watson classes and do some engineering of our own to make this work.
USA408 365 4638
1301 Shoreway Road, Suite 160,
Belmont, CA 94002
Whether you are a large enterprise looking to augment your teams with experts resources or an SME looking to scale your business or a startup looking to build something.
We are your digital growth partner.
Tel:
+1 408 365 4638
Support:
+1 (408) 512 1812


COMMENTS ()
Tweet