
Let’s begin with a scenario. Imagine you are creating a next generation social media application. An application that will revolutionize the way people interact. You expect it to be a great success in future. You are very excited and much motivated.
Since the application will be used by a massive population, you plan it to provide a Website and few mobile applications. Now you need to decide an architecture for this application.
Old school way of designing such application was to create one large application that will have everything in it. A database, a business layer, an emailer, an API, a front-end layer, etc. Such kind of architecture is known as Monolithic Architecture. There is not much wrong with this approach when the application is small or moderate in its code-base.
However, when we talk about creating a very large code-base, the limitations start to pop up. First limitation comes when we decide to scale the application to support an extremely large user base. And the second comes with the maintainability of the code-base itself.
Consider the figure below, which is a scaling or scalability cube:
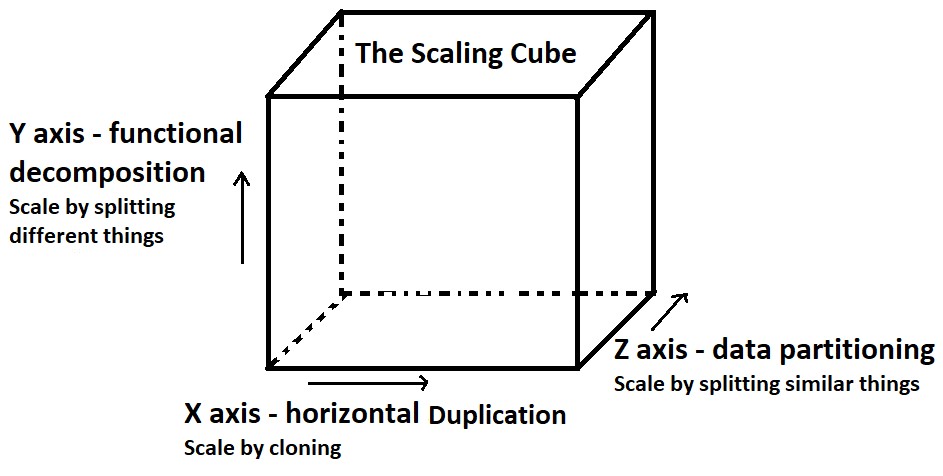
This cube was first introduced in a book named “The Art of Scalability” by Martin L. Abbott and Michael T. Fisher. The cube defines the 3 dimensions of scaling a software application.
The one large application (often called as Monolithic Architecture) solution can be scaled using X-axis and Z-axis. However since there is only one large code-base, the scaling using Y-axis cannot be done.
Upon deploying the monolith solution, in-order to scale it we would need to create multiple clones of the complete solution (X-axis scaling). And/or we can create different deployments based on data partitioning, e.g. one deployment serves free users and the other serves premium users (Z-axis scaling). Fine enough, so is it a problem if we cannot scale over Y-axis?
When such an application starts growing too much, it becomes difficult to add or replace developers. The developers will be dependent on each other, for example, an issue within the back-end code would impact the front-end development very easily.
Setting up the development environment can also become a nightmare. This makes continuous development very difficult, and developers may not be able to work independently. This also hinders the productivity and the code quality.
By the time, if the technologies that were used to develop the application get deprecated, this large code base would slowly become a legacy software. This is because you cannot update or change the technologies in such big applications without an enormous refactoring.
Scaling the application can be difficult too. The application, when cloned for X-axis scaling, may not be able to fulfill performance needs. This is because each clone contains everything within it, e.g. connections to the databases, all the integrations, all the front-end logic, etc. This creates too much load and resources to handle for each of the clones.
Now knowing all the problems with such monolithic architecture, if you decide against using it. What can be the other solution?
So instead of creating one big application, why not we create multiple small applications on functional basis?
Microservices architecture is an approach to develop an application as a set of small independent services. Each service runs in its own independent process, and can communicate with other services using some lightweight communication protocols, e.g. HTTP.
These services can be independently deployed. Different technology stacks can be used in different services, so that the application as a whole remains relevant for a long time.
This approach is the opposite of the previously discussed monolithic architecture. It supports scaling on all the axes of scaling cube. Since the Y-axis requires functional decomposition of the application, and each service has its own responsibility and code-base, we can easily scale to this dimension.
Now we can train new developers over a particular service much easily when compared to training over one large application. You can maintain checks over code-quality easily, and continuous development also works nice with this model.
The team working on each service can choose the best technology stack for the service. If one of the services was using a technology stack that needs to be upgraded, the upgrade can be made with little effort as compared to a monolithic application.
Consider the following figure, it shows how a monolithic bulky application was having everything within a single code-base, so each deployment/clone required the usage of each and every part of code. Whereas the microservices breaks down the bulky application into small services/units based on their functionalities.

So are there any limitations or issues with this approach too?
This approach comes with a complexity of creating a distributed system. Usually there are many challenges involved with setting up of a distributed environment. Testing a service along with integrations can also be much difficult as compared to testing a system as a whole. You also have to test the integration and connectivity between services.
The team associated with a service needs to stay updated with any changes that happen in other services. Any change in interface of a service will need proper handling in other services that use it.
Another challenge is deciding how to decompose the application to create smaller units, i.e. how to create microservices. Thankfully there are some well recognized patterns of doing this. Generally people follow the Single Responsibility Principle, which means that each service must have only one responsibility. Some people create services based on their use cases.
Other people partition the system into services by the verbs, e.g. create a service implements the Logging sub-system. Another strategy is to partition by nouns or resources. This kind of service is responsible for all operations that operate on resources of the specified type.
Microservices architecture requires robust inter-service communication mechanism. Many systems use the REST APIs over HTTP, some use SOAP APIs and yet some use Remote procedure calls.
However, there is a hidden problem associated with communication between services. Think about a web server being able to call various services before rendering the output page for a particular request.
The problem is if a service calls many other services to function properly, then the latency of the caller service to perform an action will increase, just because it is dependent on other services.
A resolution to the above problem could be introducing Gateways or Middlewares in between the caller service and the called services. This intermediate layer can cache the data that passes through it.
Another resolution would be to use asynchronous communication, for example, using a publisher subscriber pattern (or a Message Bus, in other words). The message bus lets applications post requests and read responses later.
To summarize all the problems associated with this architecture in one sentence could be, “With microservices architecture, there comes an implicit complexity to manage the communication between services and the coordination between teams”.
Now we are aware what a Microservices Architecture is and how it differs from a Monolithic Architecture. Should we use Microservices or Monolithic Architecture is a debate. What should we use for the given Social Media project or any other project? This truly depends upon the nature of project and how you want to manage it.
USA408 365 4638
1301 Shoreway Road, Suite 160,
Belmont, CA 94002
Whether you are an enterprise aiming to accelerate AI adoption across your organization, an SME looking to scale through intelligent automation, or a startup building AI-powered products from the ground up. We are your trusted partner in driving end-to-end AI transformation and digital growth.
New Customers:
+1 (408) 412-3813
Existing Customers:
+1 (408) 512 1812


COMMENTS ()
Tweet